

La taille est-elle importante?
Les exigences de mémoire sont l’avantage le plus évident de la réduction de la complexité des poids internes d’un modèle. Le modèle Bitnet B1.58 peut s’exécuter en utilisant seulement 0,4 Go de mémoire, par rapport à de 2 à 5 Go pour d’autres modèles ouverts à peu près la même taille de paramètre.
Mais le système de pondération simplifié conduit également à un fonctionnement plus efficace au moment de l’inférence, avec des opérations internes qui comptent beaucoup plus sur des instructions d’ajout simples et moins sur les instructions de multiplication coûteuses en calcul. Ces améliorations de l’efficacité signifient que Bitnet B1.58 utilise de 85 à 96% en moins d’énergie par rapport aux modèles de précision complète similaires, estiment les chercheurs.
Une démo de Bitnet B1.58 fonctionnant à grande vitesse sur un processeur Apple M2.
En utilisant un noyau hautement optimisé conçu spécifiquement pour l’architecture Bitnet, le modèle Bitnet B1.58 peut également s’exécuter plusieurs fois plus rapidement que des modèles similaires fonctionnant sur un transformateur de précision complet standard. Le système est suffisamment efficace pour atteindre “les vitesses comparables à la lecture humaine (5-7 jetons par seconde)” en utilisant un seul CPU, les chercheurs écrivent (vous pouvez télécharger et exécuter ces noyaux optimisés vous-même sur un certain nombre de processeurs ARM et x86, ou l’essayer en utilisant cette démonstration Web).
Surtout, les chercheurs disent que ces améliorations ne se sont pas posées au prix de la performance sur diverses références qui testent le raisonnement, les mathématiques et les capacités de «connaissance» (bien que cette affirmation n’ait pas encore été vérifiée indépendamment). En moyenne les résultats sur plusieurs repères communs, les chercheurs ont constaté que Bitnet “atteint des capacités presque comparables aux principaux modèles dans sa classe de taille tout en offrant une efficacité considérablement améliorée”.
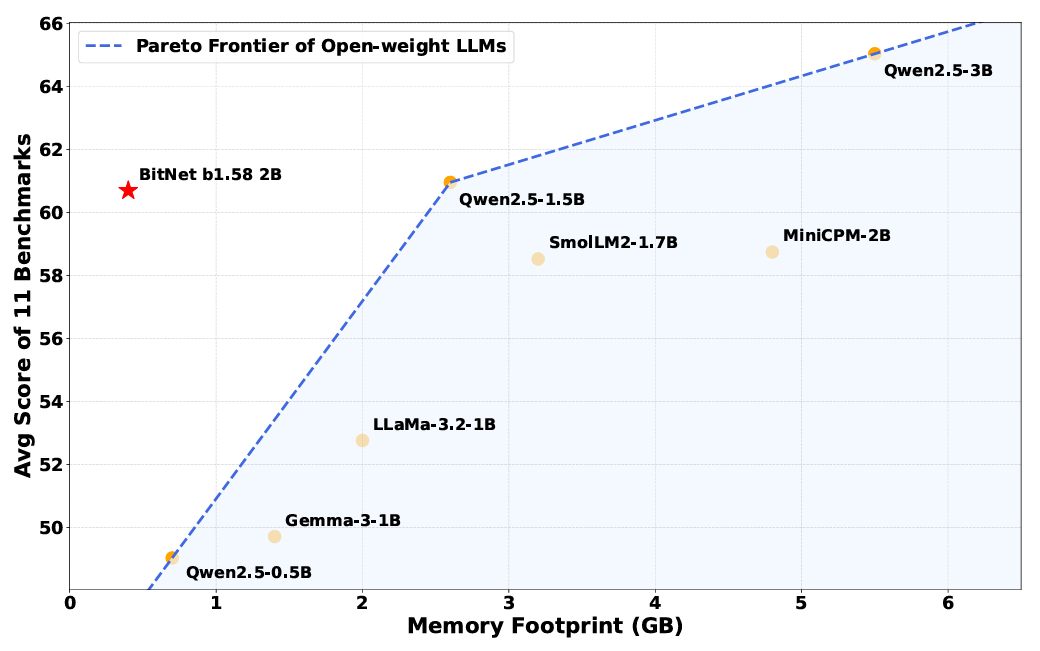
Malgré son empreinte mémoire plus petite, Bitnet fonctionne toujours de la même manière que les modèles pondérés “Full Precision” sur de nombreux repères.
Malgré son empreinte mémoire plus petite, Bitnet fonctionne toujours de la même manière que les modèles pondérés “Full Precision” sur de nombreux repères.
Malgré le succès apparent de ce modèle Bitnet “Proof of Concept”, les chercheurs écrivent qu’ils ne comprennent pas très bien pourquoi le modèle fonctionne aussi bien que avec une pondération aussi simplifiée. “Approfondir les fondements théoriques de la raison pour laquelle la formation 1 bits à grande échelle est efficace reste un espace ouvert”, écrivent-ils. Et davantage de recherches sont encore nécessaires pour faire en sorte que ces modèles Bitnet rivalisent avec la taille globale et la «mémoire» de la fenêtre de contexte des plus grands modèles d’aujourd’hui.
Pourtant, cette nouvelle recherche montre une approche alternative potentielle pour les modèles d’IA qui sont confrontés à des coûts matériels et énergétiques en spirale en fonctionnant sur des GPU coûteux et puissants. Il est possible que les modèles de “pleine précision” d’aujourd’hui soient comme des voitures musculaires qui gaspillent beaucoup d’énergie et d’efforts lorsque l’équivalent d’une belle sous-composition pourrait fournir des résultats similaires.

